以太坊挖矿源码:ethash算法
本文专门分析了以太坊的一种共识算法:实现POW的以太坊共识引擎ethash。
关键词:ethash、共识算法、pow、Dagger Hashimoto、ASIC、struct{}、nonce、FNV 哈希、位操作、epoch
Ethash
在分析以太坊挖矿源码之前,挖了一个共识引擎的坑,研究了DAG有向无环图的算法。这些是本文要研究的 Ethash 的基础。 Ethash 目前是以太坊中基于 POW 工作量证明的共识引擎(也称为挖矿算法)。它的前身是Dagger Hashimoto算法。
匕首桥本
作为以太坊挖矿算法Ethash的前身,Dagger Hashimoto旨在:
Dagger和Hashimoto其实是两个东西,
桥本算法
它是由 Thaddeus Dryja 创造的。旨在抵抗具有 IO 限制的矿工。在挖矿过程中,设置了内存读取限制。由于内存设备本身会比计算设备更便宜、更通用,因此世界各地的大公司也纷纷投入巨资进行内存升级优化,以使内存适应各种用户。场景,于是就有了随机存取内存RAM的概念,因此,现有内存可能更接近最优评价算法。桥本算法以区块链为源数据,满足上述要求1和3。
匕首算法
它是由这个人 Vitalik Buterin 发明的。它利用有向无环图DAG,实现了Memory-Hard Function,在内存中难以计算,但易于验证。它是基于每个特定场合的nonce只需要大数据总树的一小部分,并且禁止重新计算每个特定场合的nonce的子树来挖掘。因此,存储树既需要同时支持独立场合的 nonce 验证值。 Dagger 算法注定要取代现有的计算困难的纯内存算法,例如 Scrypt(莱特币使用),当它们的内存计算难度增加到真正安全时,它的计算难度和验证难度都很大。 Dagger算法被证明容易受到Sergio Lerner发明的共享内存硬件加速技术的攻击,该算法随后被放弃在其他路径的研究中。
p>
硬记忆功能
直译是记忆难度功能,是为地址矿机而生的一个想法。我们知道挖矿依赖于我们的计算机,但是一些硬件制造商会制造专门用于挖矿的硬件设备,它们并不是完整的 PC,例如 ASIC、GPU 和 FPGA(我们经常听到 GPU 挖矿等)。所以这些设备作为矿机是超越普通PC挖矿的存在,不符合我们区块链的去中心化精神,所以必须让矿机平等。
那么如何让矿机平等呢?
其实我在讲Dagger算法的时候就提到了。这里我换一种方式来介绍。现在 CPU 是多核的。在计算能力方面,如果 CPU 有几个核心,它可以同时模拟几个设备。并行挖矿Mine自然效率更高,但这里使用的测量对象是内存,一台计算机总共只有一个内存。做过java多线程开发的朋友都知道,机器性能再高,我们写的程序都是单线程的,所以在高端多核电脑上运行的程序和在高端多核电脑上运行的程序的区别低端的单核电脑并不大,只要它们的单核计算能力和内存大小一样。所以这是相同的原理。通过 Dagger 算法,我们将挖矿过程锁定在以内存衡量的硬件性能上。只要采用“将一堆数据插入内存”的方法,就无法进行多核并行处理,降低了硬件。 ASIC的计算优势只与内存大小有关,因此无论是PC、ASIC、GPU还是FPGA,都可以达到平等挖矿的要求。
两个问题的研究
在Dagger和Dagger Hashimoto的算法中,有两个问题被搁置了以太坊挖矿原理详解,
匕首桥本算法
(与桥本不同)Dagger Hashimoto不直接使用区块链作为数据源,而是使用1GB自定义生成的数据集缓存。
此数据集基于每 N 个块更新一次的块数据。数据集是使用 Dagger 算法生成的,允许自己有效地计算特定于每个轻客户端验证算法的 nonce。
(与 Dagger 不同)Dagger Hashimoto 克服了 Dagger 的缺点,因为它用于查询块数据的数据集是半永久性的,并且仅偶尔更新(例如每周一次)。这意味着生成数据集将非常容易,因此 Sergio Lerner 有争议的共享内存加速变得微不足道。
挖矿补充
之前写过一篇关于挖矿的文章,这部分是对挖矿的补充。
以太坊会过渡到POS(proof-of-stake),代替传统的POW,会淘汰挖矿,所以现在不建议做矿工(前期购买设备成本高,POS实施前可能无法返还原金额)。
挖掘以太=网络安全=验证估算
目前以太坊的POW算法是Ethash,
Ethash 算法包括找到一个输入到算法中的 nonce 值,该算法会根据特定难度产生低于阈值的结果。
POW算法的关键在于,除了蛮力枚举,没有办法找到这个nonce值,但是输出结果很简单,很容易验证。如果输出结果是均匀分布的,我们可以保证找到一个nonce值所需的平均时间取决于难度阈值,所以我们可以通过调整难度阈值来控制找到新块的时间,也就是控制块速度原理。
DAG
Ethash 的 POW 是硬记忆的,支持矿机抗性。这意味着POW计算需要选择依赖nonce值和块头的固定资源子集。
这个资源(大约 1G 大小)是 DAG!
我的时代
每 30,000 个区块生成一个有向无环图的 DAG 需要数小时。这个 DAG 称为 epoch, I(为了便于记忆,请参考 Qin II)。 DAG 仅取决于块高度。它可以预先生成。如果没有预生成,客户端需要等待预生成过程结束,才能继续生成区块。除非客户端实际上提前预先缓存了 DAG,否则网络在每个 epoch 转换期间可能会遇到巨大的块延迟。
特殊情况:当你从头开始一个节点时,只有在创建了真实世界的 DAG 之后才会开始挖矿。
挖矿奖励

分为三个部分:
Ethash
Ethash 算法路线图:
上面提到的大型数据集每 30,000 个区块更新一次,因此绝大多数矿工的工作是读取数据集而不是更改数据集。
pkg ethash源码分析
上面的概念我们都抽象出来了,包括POW、挖矿、Ethash原理流程等,接下来我们将把这些理论知识放到源码中来分析具体实现。正如我们的标题,本文主要分析ethash算法,所以整个源码范围仅限于go-ethereum/consensus/ethash包,它实现了ethash pow的共识引擎。
进入
必须有分析源代码的入口。本条目是《以太坊源码机制:挖矿》中挖的坑“封印法”。
go-ethereum/consensus/consensus.go接口中定义了以下方法,对应上面的“Seal方法”。接口方法定义如下:
Seal(chain ChainReader, block *types.Block, stop <-chan struct{}) (*types.Block, error)//该方法通过输入一个包含本地矿工挖出的最高区块在主干上生成一个新块。复制
参数包括ChainReader、Block、stop结构体信号,返回主链上新的区块实体。
// 定义了一些方法,用于在区块头验证以及叔块验证期间,访问本地区块链。
type ChainReader interface {
// 获取区块链的链配置
Config() *params.ChainConfig
// 从本地链获取当前块头
CurrentHeader() *types.Header
// 通过hash和number从主链中获取一个区块头
GetHeader(hash common.Hash, number uint64) *types.Header
// 通过number从主链中获取一个区块头
GetHeaderByNumber(number uint64) *types.Header
// 通过hash从主链中获取一个区块头
GetHeaderByHash(hash common.Hash) *types.Header
// 通过hash和number从主链中获取一个区块
GetBlock(hash common.Hash, number uint64) *types.Block
}复制
总结一下,ChainReader定义了几种方法:从本地区块链获取配置和区块头,从主链获取区块头和区块。参数条件包括hash和number,可以任意组合。
// Block代表以太坊区块链中的一个完整的区块
type Block struct {
header *Header // 区块包括头
uncles []*Header // 叔块
transactions Transactions // 交易集合
// caches缓存
hash atomic.Value
size atomic.Value
// Td用于core包存储所有的链上的难度
td *big.Int
// 这些字段用于eth包来跟踪inter-peer内部端点区块的接替
ReceivedAt time.Time
ReceivedFrom interface{}
}复制
综上所述,除了区块头、叔块和交易信息打包存储在知名区块之外,区块还有缓存的内容,以及每个区块到链上的难度值,并用于跟踪内部端点的字段。

stop 是一个空结构体作为信号源。
关于空结构的讨论,为什么struct{}经常出现在go中?
在go中,除了struct{}类型,其他类型都是width,占用存储,而struct{}没有字段,没有方法,width为0,灵活性高,不占用内存空间,可能会受到青睐根据 Gopher 的原因。
密封剂
seal 方法有两种实现方式。我们选择 ethash。该方法存在于consensus/ethash/sealer.go 文件中。第一个功能是执行密封。我们先来看方法的声明部分:
// 尝试找到一个nonce值能够满足区块难度需求。
func (ethash *Ethash) Seal(chain consensus.ChainReader, block *types.Block, stop <-chan struct{}) (*types.Block, error) {复制
可见该方法属于Ethash的指针对象,
type Ethash struct {
// cache配置
cachedir string // 缓存位置
cachesinmem int // 在内存中缓存的数量
cachesondisk int // 在硬盘中缓存的数量
// DAG挖矿数据集配置
dagdir string // DAG位置,存储全部挖矿数据集
dagsinmem int // 在内存中DAG的数量
dagsondisk int // 在硬盘中DAG的数量
// 内存cache
caches map[uint64]*cache // 内存缓存,可反复使用避免再生太频繁
fcache *cache // 为了下一世估算的预生产缓存
// 内存数据集
datasets map[uint64]*dataset // 内存数据集,可反复使用避免再生太频繁
fdataset *dataset // 为了下一世估算的预生产数据集
// 挖矿相关字段
rand *rand.Rand // 随机工具,用来为nonce做适当的种子
threads int // 如果在挖矿,代表挖矿的线程编号
update chan struct{} // 更新挖矿中参数的通道
hashrate metrics.Meter // 测量跟踪平均哈希率
// 以下字段是用于测试
tester bool // 是否使用一个小型测试数据集的标志位
shared *Ethash // 共享pow模式,无法再生缓存
fakeMode bool // Fake模式,是否取消POW检查的标志位
fakeFull bool // 是否取消所有共识规则的标志位
fakeFail uint64 // 未通过POW检查的区块号(包含fake模式)
fakeDelay time.Duration // 验证工作返回消息前的休眠延迟时间
lock sync.Mutex // 为了内存中的缓存和挖矿字段,保证线程安全
}复制
为了更好的理解下面的代码,我们需要分析一下区块头的数据结构:
type Header struct {
ParentHash common.Hash `json:"parentHash" gencodec:"required"`
UncleHash common.Hash `json:"sha3Uncles" gencodec:"required"`
Coinbase common.Address `json:"miner" gencodec:"required"`
Root common.Hash `json:"stateRoot" gencodec:"required"`
TxHash common.Hash `json:"transactionsRoot" gencodec:"required"`
ReceiptHash common.Hash `json:"receiptsRoot" gencodec:"required"`
Bloom Bloom `json:"logsBloom" gencodec:"required"`
Difficulty *big.Int `json:"difficulty" gencodec:"required"`
Number *big.Int `json:"number" gencodec:"required"`
GasLimit *big.Int `json:"gasLimit" gencodec:"required"`
GasUsed *big.Int `json:"gasUsed" gencodec:"required"`
Time *big.Int `json:"timestamp" gencodec:"required"`
Extra []byte `json:"extraData" gencodec:"required"`
MixDigest common.Hash `json:"mixHash" gencodec:"required"`
Nonce BlockNonce `json:"nonce" gencodec:"required"`
}复制
可以看到一个区块头包含父区块哈希值、叔块哈希值、Coinbase节点账户地址、状态根、交易哈希、接收哈希、日志、难度值、区块数、最低支付gas、成本gas , 时间戳, 额外数据, 混合哈希, nonce 值 (8 字节)。我们需要对这些区块头的成员属性有一个清晰的认识,才能更好的理解后面的源码内容。接下来我们继续Seal方法,完整代码如下:
func (ethash *Ethash) Seal(chain consensus.ChainReader, block *types.Block, stop <-chan struct{}) (*types.Block, error) {
// fake模式立即返回0 nonce
if ethash.fakeMode {
header := block.Header()
header.Nonce, header.MixDigest = types.BlockNonce{}, common.Hash{}
return block.WithSeal(header), nil
}
// 共享pow的话,则转到它的共享对象执行Seal操作
if ethash.shared != nil {
return ethash.shared.Seal(chain, block, stop)
}
// 创建一个runner以及它指挥的多重搜索线程
abort := make(chan struct{})
found := make(chan *types.Block)
ethash.lock.Lock() // 线程上锁,保证内存的缓存(包含挖矿字段)安全
threads := ethash.threads // 挖矿的线程s
if ethash.rand == nil {// rand为空,则为ethash的字段rand赋值
// 获得种子
seed, err := crand.Int(crand.Reader, big.NewInt(math.MaxInt64))
if err != nil {// 执行失败,有报错
ethash.lock.Unlock() // 先解锁
return nil, err // 程序中止,直接返回空块和报错信息
}
ethash.rand = rand.New(rand.NewSource(seed.Int64())) // 执行成功,拿到合法种子seed,通过其获得rand对象,赋值。
}
ethash.lock.Unlock() // 解锁
if threads == 0 {// 挖矿线程编号为0,则通过方法返回当前物理上可用CPU编号
threads = runtime.NumCPU()
}
if threads < 0 { // 非法结果
threads = 0 // 置为0,允许在本地或远程没有额外逻辑的情况下,取消本地挖矿操作
}
var pend sync.WaitGroup // 创建一个倒计时锁对象,go语法参照 http://www.cnblogs.com/Evsward/p/goPipeline.html#sync.waitgroup
for i := 0; i < threads; i++ {
pend.Add(1)
go func(id int, nonce uint64) {// 核心代码通过闭包多线程技术来执行。
defer pend.Done()
ethash.mine(block, id, nonce, abort, found) // Seal核心工作
}(i, uint64(ethash.rand.Int63()))//闭包第二个参数表达式uint64(ethash.rand.Int63())通过上面准备好的rand函数随机数结果作为nonce实参传入方法体
}
// 直到seal操作被中止或者找到了一个nonce值,否则一直等
var result *types.Block // 定义一个区块对象result,用于接收操作结果并作为返回值返回上一层
select { // go语法参照 http://www.cnblogs.com/Evsward/p/go.html#select
case <-stop:
// 外部意外中止,停止所有挖矿线程
close(abort)
case result = <-found:
// 其中一个线程挖到正确块,中止其他所有线程
close(abort)
case <-ethash.update:
// ethash对象发生改变,停止当前所有操作,重启当前方法
close(abort)
pend.Wait()
return ethash.Seal(chain, block, stop)
}
// 等待所有矿工停止或者返回一个区块
pend.Wait()
return result, nil
}复制
上述Seal方法体对ethash的各种状态和线程资源的控制进行checksum过程处理。再来看看Seal核心工作的内容(sealer.go文件只有两个功能,一个是Seal方法,一个是mine方法,可见Seal方法是外部的,mine方法是内部方法,只能被当前的ethash包域调用):我的方法
// mine函数是真正的pow矿工,用来搜索一个nonce值,nonce值开始于seed值,seed值是能最终产生正确的可匹配可验证的区块难度
func (ethash *Ethash) mine(block *types.Block, id int, seed uint64, abort chan struct{}, found chan *types.Block) {
// 从区块头中提取出一些数据,放在一个全局变量域中
var (
header = block.Header()
hash = header.HashNoNonce().Bytes()
target = new(big.Int).Div(maxUint256, header.Difficulty) // 后面有大用,这是用来验证的target
number = header.Number.Uint64()
dataset = ethash.dataset(number)
)
// 开始生成随机nonce值知道我们中止或者成功找到了一个合适的值
var (
attempts = int64(0) // 初始化一个尝试次数的变量,下面会利用该变量耍一些花枪
nonce = seed // 初始化为seed值,后面每次尝试以后会累加
)
logger := log.New("miner", id)
logger.Trace("Started ethash search for new nonces", "seed", seed)
for {
select {
case <-abort: // 中止命令
// 挖矿中止,更新状态,中止当前操作,返回空
logger.Trace("Ethash nonce search aborted", "attempts", nonce-seed)
ethash.hashrate.Mark(attempts)
return
default: // 默认执行
// 我们没必要在每一次尝试nonce值的时候更新hash率,可以在尝试了2的X次方nonce值以后再更新即可
attempts++ // 通过次数attemp来控制
if (attempts % (1 << 15)) == 0 {// 这里是定的2的15次方,位操作符请参考 http://www.cnblogs.com/Evsward/p/go.html#%E5%B8%B8%E9%87%8F
ethash.hashrate.Mark(attempts) // 满足条件了以后,要更新ethash的hash率字段的状态值
attempts = 0 // 重置尝试次数
}
// 为这个nonce值计算pow值
digest, result := hashimotoFull(dataset, hash, nonce) // 调用的hashimotoFull函数在本包的算法库中,后面会介绍。
if new(big.Int).SetBytes(result).Cmp(target) <= 0 { // 验证标准,后面介绍
// 找到正确nonce值,创建一个基于它的新的区块头
header = types.CopyHeader(header)
header.Nonce = types.EncodeNonce(nonce) // 将输入的整型值转换为一个区块nonce值
header.MixDigest = common.BytesToHash(digest) // 将字节数组转换为Hash对象【Hash是32位的根据任意输入数据的Keccak256哈希算法的返回值】
// 封装返回一个区块
select {
case found <- block.WithSeal(header):
logger.Trace("Ethash nonce found and reported", "attempts", nonce-seed, "nonce", nonce)
case <-abort:
logger.Trace("Ethash nonce found but discarded", "attempts", nonce-seed, "nonce", nonce)
}
return
}
nonce++ // 累加nonce
}
}
}
复制
挖矿方式主要是nonce的操作和区块头的重构。我们还在评论中为nonce尝试的工作留下了一个坑。这部分内容会在算法库中介绍。
算法
ethash 包包含几个以算法开头的文件。这些文件的内容是支持挖矿操作的核心 pow 算法。首先,我们继续研究上面留下的坑。
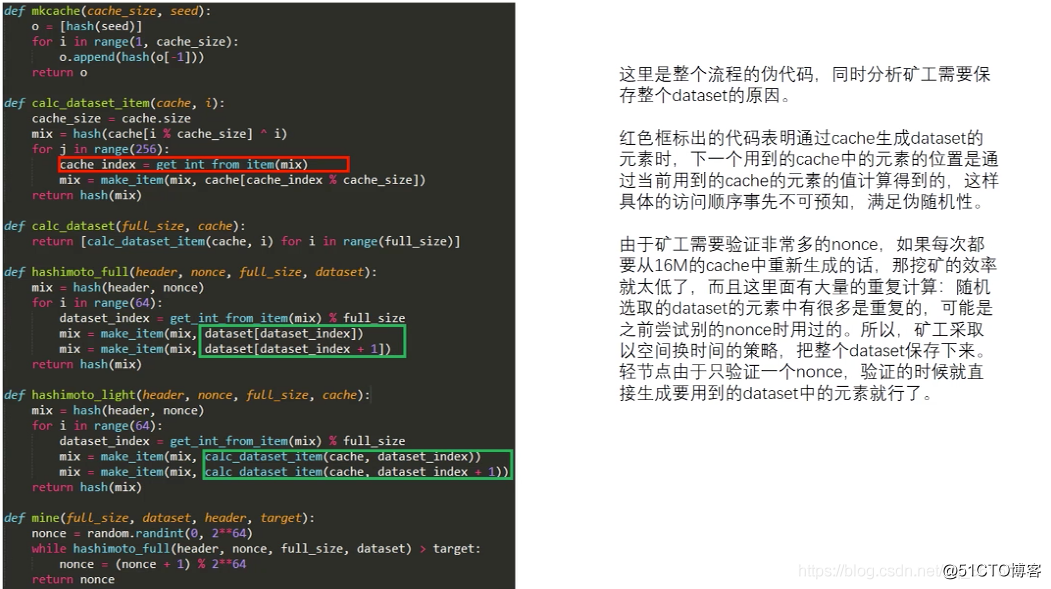
hashimoto全功能
这个函数位于ethash/algorithm.go文件中,
// 在传入的数据集中通过hash和nonce值计算加密值
func hashimotoFull(dataset []uint32, hash []byte, nonce uint64) ([]byte, []byte) {
// 本函数核心代码段:定义一个lookup函数,用于在数据集中查找数据
lookup := func(index uint32) []uint32 {
offset := index * hashWords // hashWords是上面定义的常量值= 16
return dataset[offset : offset+hashWords]
}
// hashimotoFull函数做的工作就是将原始数据集进行了读取分割,然后传给hashimoto函数。
return hashimoto(hash, nonce, uint64(len(dataset))*4, lookup)
}复制
桥本函数
继续分析。上面的hashimotoFull函数返回hashimoto函数的返回值。我们已经在上面的概念部分介绍了桥本算法。源码看不懂的可以回到上面仔细理解再回到这里。继续学习。
// 该函数与hashimotoFull有着相同的愿景:在传入的数据集中通过hash和nonce值计算加密值
func hashimoto(hash []byte, nonce uint64, size uint64, lookup func(index uint32) []uint32) ([]byte, []byte) {
// 计算数据集的理论的行数
rows := uint32(size / mixBytes)
// 合并header+nonce到一个40字节的seed
seed := make([]byte, 40) // 创建一个长度为40的字节数组,名字为seed
copy(seed, hash)// 将区块头的hash(上面提到了Hash对象是32字节大小)拷贝到seed中。
binary.LittleEndian.PutUint64(seed[32:], nonce) // 将nonce值填入seed的后(40-32=8)字节中去,(nonce本身就是uint64类型,是64位,对应8字节大小),正好把hash和nonce完整的填满了40字节的seed
seed = crypto.Keccak512(seed) // seed经历一遍Keccak512加密
seedHead := binary.LittleEndian.Uint32(seed) // 从seed中获取区块头,代码后面详解
// 开始与重复seed的混合
mix := make([]uint32, mixBytes/4)// mixBytes常量= 128,mix的长度为32,元素为uint32,是32位,对应为4字节大小。所以mix总共大小为4*32=128字节大小
for i := 0; i < len(mix); i++ {
mix[i] = binary.LittleEndian.Uint32(seed[i*4:])// 共循环32次,前16和后16位的元素值相同
}
// 做一个temp,与mix结构相同,长度相同
temp := make([]uint32, len(mix))
for i := 0; i < loopAccesses; i++ { // loopAccesses常量 = 64,循环64次
parent := fnv(uint32(i)^seedHead, mix[i%len(mix)]) % rows // mix[i%len(mix)]是循环依次调用mix的元素值,fnv函数在本代码后面详解
for j := uint32(0); j < mixBytes/hashBytes; j++ {
copy(temp[j*hashWords:], lookup(2*parent+j))// 通过用种子seed生成的mix数据进行FNV哈希操作以后的数值作为参数去查找源数据(太绕了)拷贝到temp中去。
}
fnvHash(mix, temp) // 将mix中所有元素都与temp中对应位置的元素进行FNV hash运算
}
// mix大混淆
for i := 0; i < len(mix); i += 4 {
mix[i/4] = fnv(fnv(fnv(mix[i], mix[i+1]), mix[i+2]), mix[i+3])
}
// 最后有效数据只在前8个位置,后面的数据经过上面的循环混淆以后没有价值了,所以将mix的长度减到8,保留前8位有效数据。
mix = mix[:len(mix)/4]
digest := make([]byte, common.HashLength) // common.HashLength=32,创建一个长度为32的字节数组digest
for i, val := range mix {
binary.LittleEndian.PutUint32(digest[i*4:], val)// 再把长度为8的mix分散到32位的digest中去。
}
return digest, crypto.Keccak256(append(seed, digest...))
}复制
这个函数除了被hashimotoFull函数调用外,还会被hashimotoLight函数调用。顾名思义,hashimotoLight 是相对于 hashmotoFull 存在的。以后有机会会介绍 HashimotoLight(看看能不能绕道走)。
下划线和位运算|
seedHead := binary.LittleEndian.Uint32(seed) 在上面的代码中,我们挑出一个单一的做法,跳转到内部方法:
func (littleEndian) Uint32(b []byte) uint32 {
_ = b[3] // bounds check hint to compiler; see golang.org/issue/14808
return uint32(b[0]) | uint32(b[1])<<8 | uint32(b[2])<<16 | uint32(b[3])<<24
}复制
FNV 哈希算法

FNV 来源于三位创始人的名字。我们知道哈希算法最重要的目标是均匀分布(高度分散),避免冲突。相似的源数据最好加密后完全不同,即使只有一个字母不同,FNV哈希算法就是这样一种算法。
func fnv(a, b uint32) uint32 {
return a*0x01000193 ^ b
}
func fnvHash(mix []uint32, data []uint32) {
for i := 0; i < len(mix); i++ {
mix[i] = mix[i]*0x01000193 ^ data[i]
}
}复制
0x01000193是FNV散列算法的散列素数(素数,又称素数,只能被1和自身整除)。散列算法将基于一个常数执行散列操作。 0x01000193 是 32 位数据的 FNV 哈希素数。
认证方式
我们一直提到 pow 是很难计算的。上面长长的一章深刻反映了这一点,但是pow很容易验证,所以本节讨论ethash的pow验证方法,也很容易找到。是我在上面的挖矿方法评论中留下的坑:
new(big.Int).SetBytes(result).Cmp(target) <= 0复制
我们的核心计算nonce对应加密值摘要方法hashimoto算法返回一个摘要和一个结果两个值,从这行代码可以看出,结果的值与验证方法有关。结果最终在hashimoto算法中用crypto.Keccak256(append(seed, digest...)的Keccak256加密,在参数列表中也看到了digest值。得到结果值后,上面的表达式必须执行这行代码以太坊挖矿原理详解,这行的表达式很简单,主要意思是比较结果值和目标值,小于等于0,就通过了。
那么目标是什么?
target定义在mine方法体的第一个变量声明部分,
target = new(big.Int).Div(maxUint256, header.Difficulty)复制
可以看出,target的定义是根据block header中的难度值来计算的。因此,这验证了我们在概念部分首先提到的,我们可以通过调整 Difficulty 值来控制 pow 操作的难度,生成正确 nonce 的难度,从而达到可控 pow 工作量的目标。
总结
看完这里的代码,已经完成了一个闭环。结合之前的“挖矿”,我们已经走过了以太坊pow的全过程。我没有放松整个过程。从内核的入口,我们把源码放到了最底层(其实在目前为止的过程中,以太坊的 pow 并没有像我想象的那样真正使用 DAG)。至此,我们对 pow 和以太坊 ethash 的实现有了深入的了解和理解。我相信如果让我们实现一套pow,也是完全有能力的。如果您在阅读本文时有任何问题,可以给我留言,我会及时回复。
参考文献
go-ethereum源码、以太坊官方文档、网络术语解释文章
更多文章,请前往 Awake 博客园。